2. Modelado de Datos Estructurados
2.1 Definición
- Son aquellos datos fuertemente tipados
- Poseen una estructura o estilo rígido
- Por lo general se asocian a una base de datos (relacional u orientada a
objetos).
2.2 Administración de bases de datos
2.2.1 Roles
La información es el centro de todas las aplicaciones de hoy en día.
La administración de la información es una tarea que tiene demasiada responsabilidad ya que el éxito o fracaso depende directamente de ella.
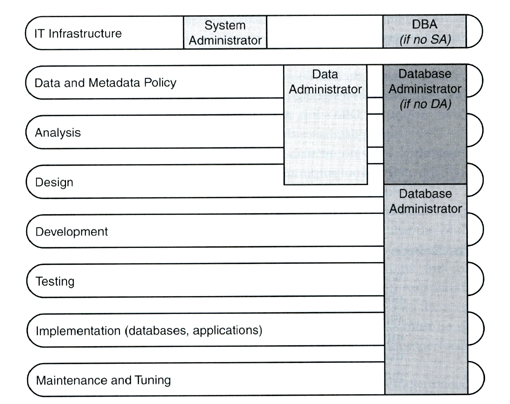
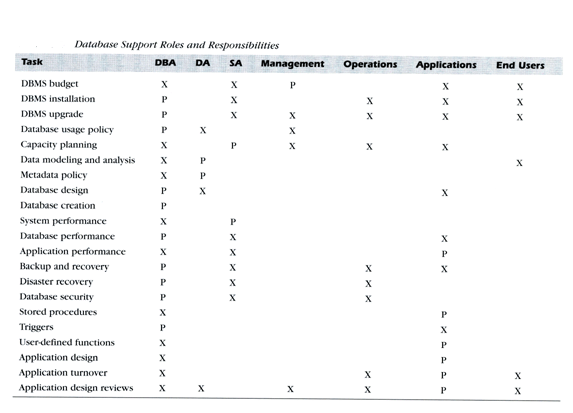
Hablar de la administración de información es hablar de roles, algunas organizaciones (dependiendo de los recursos humanos) los dividen en:
- Data Administrator (DA): quienes son las personas encargadas de lidiar con los aspectos comerciales o profesionales de los datos.
- Database Administrator (DBA): encargado de los aspectos técnicos.
Nota: en pequeñas organizaciones ambos roles son ejecutados por la misma persona, a la cual por lo general se le conoce como DBA.
otros roles que no están directamente relacionados con la información pero que interactúan directamente con las personas mencionadas son:
- System Administrator (SA): quien se encarga de toda la infraestructura de servidores, discos, firewalls, etc.
- Programmers/Developers: el dolor de cabeza de los DBAs.
- Managers: a quien rendirle cuentas.
- Customers/End users: gente sin ningún conocimiento técnico.
DBA vs DA
DBA vs DA vs SA
Habilidades requeridas para ser un "buen" DBA:
- Técnicas:
- Conocimiento de bases de datos
- Conocimiento de desarrollo de aplicaciones
- Conocimiento de administración de sistemas/servidores
- Comerciales:
- Entender procesos de una organización
- Seguir tendencias de la industria
- Sociales
- Comunicación
- Administración
- Resolución de problemas
- Educación continua
Aspectos a considerar una oferta de trabajo de DBA:
- La compañía ofrece capacitación regular ?
- Se permite contactar regularmente a grupos de usuarios locales ?
- Existen DBA de respaldo o solamente uno de 24/7 ?
- Existen DBAs y SAs o se espera realizar ambas actividades ?
- Cómo es la relación con las personas de desarrollo ?
- El DBA es tomado en cuenta para cuestiones de revisiones, presupuestos, etc. ?
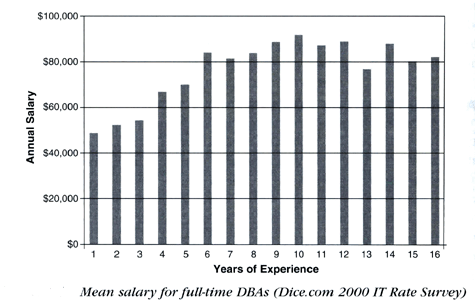
Y que hay acerca del salario ??
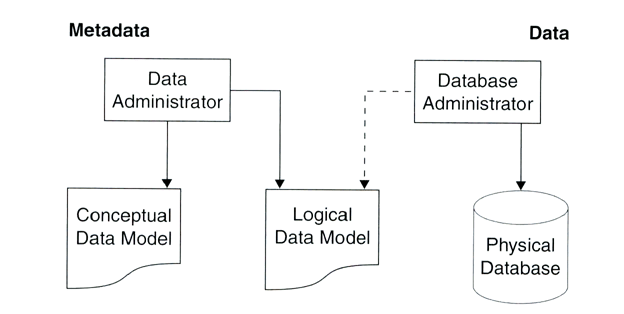
2.3 Modelado de Datos
2.3.1 Definición
- Es el proceso de analizar los aspectos de interés para una organización
y la relación que tienen unos con otros.
- Resulta en el descubrimiento y documentación de los recursos de datos
del negocio.
- El modelado hace la pregunta " Qué ? " en lugar de "
Cómo ? ", esta última orientada al procesamiento de los
datos.
- Es una tarea difícil, bastante difícil, pero es una actividad
necesaria cuya habilidad solo se adquiere con la experiencia.
2.3.2 Metas y beneficios
- Registrar los requerimientos de datos de un proceso de negocio.
- Dicho proceso puede ser demasiado complejo y se tendrá que crear
un "enterprise data model", el cual deberá estar constituído
de líneas individuales.
- Permite observar:
- Patrones de datos
- Usos potenciales de los datos
2.3.4 Tipos de modelos de datos
Basicamente son 3:
- Conceptual: muy general y abstracto, visión general del negocio/institución.
- Lógico: versión completa que incluye todos los detalles acerca
de los datos.
- Físico: esquema que se implementara en un manejador de bases de datos
(DBMS).
2.4 Modelado de Datos Conceptual y Lógico
Algunos aspectos a considerar al momento de realizar el modelado/análisis
- No pensar físicamente, pensar conceptualmente
- No pensar en procesos, pensar en estructura
- No pensar en navegación, pensar en términos de relaciones
2.4.1 Modelo Entidad Relación
Generalmente todo modelo tiene una representación gráfica, para
el caso de datos el modelo mas popular es el modelo entidad-relación
o digrama E/R.
Se denomina asi debido a que precisamente permite representar relaciones entre
entidades (objetivo del modelado de datos).
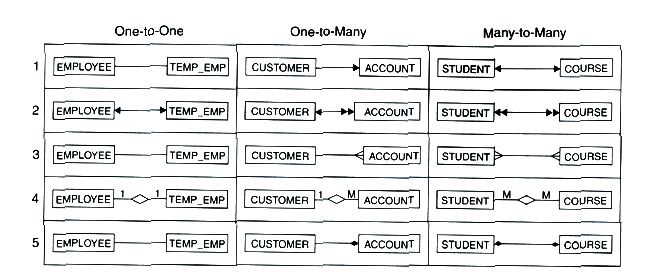
La figura 2.1 muestra distintos ejemplos de notaciones, en realidad todas muy
similares.
Figura 2.1 Notación E/R (1) Ross, (2) Bachmann, (3) Martin,
(4) Chen, (5) Rumbaugh
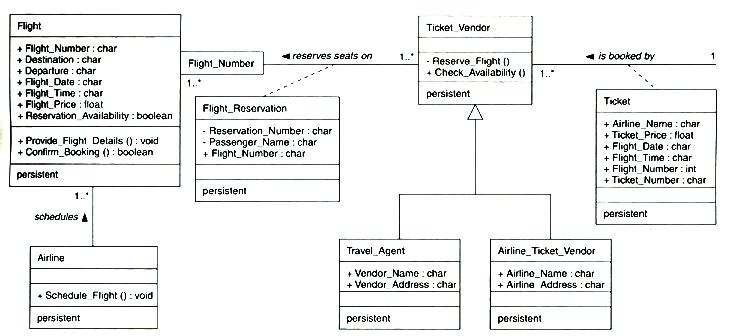
También debido al aumento de popularidad y uso de UML también
se puede emplear dicha notación (figura 2.3).
Figura 2.3 Notación UML
Lo importante es que en toda organización se debe establecer un estándar
que deben seguir todos los modelos de la misma.
El modelo debe estar compuesto por:
- Entidades: todo lo que existe y es capaz de ser descrito (sustantivo).
- Atributos: es una característica (adjetivo) de una entidad que puede
hacer 1 de tres cosas:
- Identificar
- Relacionar
- Describir
- Relaciones: la conexión que existe entre 2 entidades (verbo).
- Cardinalidad: número de ocurrencias que pueden existir entre un par
de entidades.
- Super llave: conjunto de uno o más atributos que "juntos"
identifican de manera única a una entidad
- Llave candidata: es una super llave mínima
- Llave primaria: la seleccionada para identificar a los elementos de un conjunto
de entidades.
Componentes simbólicos
 Atributos: Nombre, Edad, Semestre, Id.
Atributos: Nombre, Edad, Semestre, Id.
 Entidades: Alumno, Salón, Profesor.
Entidades: Alumno, Salón, Profesor.
 Entidades Débiles: No tienen llaves primarias.
Entidades Débiles: No tienen llaves primarias.
 Generalización: Agrupa propiedades en común a diferentes
objetos.
Generalización: Agrupa propiedades en común a diferentes
objetos.
 Relación
Relación
 Cardinalidad
Cardinalidad
|
Figura 2.4 Componentes simbólicos E/R
Guías de nombramiento
Es importante mantener guías o reglas para poder tener una documentación
uniforme y consistente de todos los datos.
- Entidades: una sola palabra (en singular) y con mayúsculas
- Atributos:
- FirstName
- first_name
- de relacion: VendorID, ProductName
- Valores: definir que valores son válidos (NULL no es un valor)
Relaciones de Cardinalidad
 (Muchos a Muchos)
(Muchos a Muchos)
 (Uno a Muchos)
(Uno a Muchos)
 (Uno a Uno)
(Uno a Uno)
|
Figura 2.5 Relaciones Modelo E/R
Ejemplo Modelo E-R
Figura 2.5 Ejemplo Modelo E/R
Figura 2.5 Modelo E/R en E/R
Generalización
Figura 2.7 Generalización
2.4.2 Conversión a tablas (esquema de datos)
El modelo es una representación visual que gráficamente nos da
una perspectiva de como se encuentran los datos involucrados en un proyecto
u organización.
Pero el modelo no nos presenta propiamente una instancia de los datos, un ejemplo
que muestre con claridad algunas datos de muestra y como se relacionan en realidad.
Por eso es conveniente crear un "esquema", el cual consiste de tablas
las cuales en sus renglones (tuplas) contienen instancias de los datos.
Las tablas 2.1 y 2.3 muestran las reglas que se deben seguir para poder crear
dicho esquema.
modelo e-r conversión a tablas
- una tabla por cada conjunto de entidades
- nombre de tabla = nombre de conjunto de entidades
- una tabla por cada conjunto de relaciones m-m
- nombre de tabla = nombre de conjunto de relaciones
- definición de columnas para cada tabla
- conjuntos fuertes de entidades
- columnas = nombre de atributos
- conjuntos débiles de entidades
- columnas = llave_primaria (dominante) U atributos(subordinado)
- conjunto de relaciones R (m-m) entre A, B
- columnas (R) = llave_primaria (A) U llave_primaria (B) U atributos(R)
- conjunto de relaciones R (1-1) entre A y B
- columnas (A) = atribs(A) U llave primaria(B) U atributos(R)
- conjunto de relaciones R (1-m) entre A y B
- columnas (B) = atribs(B) U llave primaria(A) U atributos(R)
|
Tabla 2.1
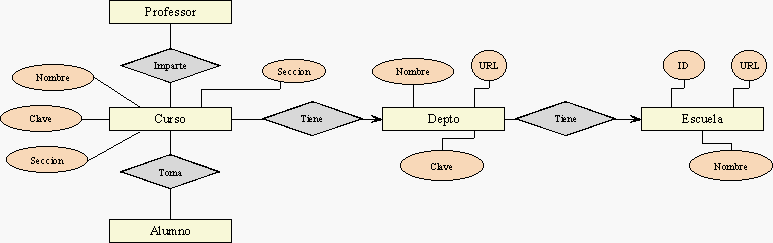
Para el ejemplo de la Figura 2.5 tendríamos:
escuela
departamento
| clave_depto |
url |
nombre |
id_escuela |
curso
| clave_curso |
seccion |
nombre |
clave_depto |
profesor
estudiante
profesor_curso
estudiante_curso
|
modelo e-r
de generalización a tablas
dos posibilidades:
- crear una tabla para el conjunto de entidades A de mayor nivel
- columnas (A) = atributos(A)
- para cada conjunto de entidades B de menor nivel, crear una tabla
tal que columnas
- (B) = atributos (B) U llave_primaria (A)
- si A es un conjunto de entidades de mayor nivel para cada conjunto
de entidades B de menor nivel, crear una tabla tal que:
columnas (B) = atributos (B) U atributos (A)
|
Tabla 2.3
2.4.3 Normalización
Una vez creadas las tablas hay que verificar si aún se puede reducir
u optimizar de alguna manera.
2.4.3.1 Dependencias funcionales
Es identificar aquellos atributos que dependen de otros y que generalizan el
concepto de super-llave
Ejemplo:
ID ---> Nombre
ID --> Puesto --> Sueldo
2.4.3.2 Primera forma normal
Una tabla se encuentra en 1a NF, si todos sus atributos son atómicos
(indivisibles)
El ejemplo clásico:
| nombre |
dirección |
teléfono |
En 1a. NF
| nombre |
apellido_paterno |
apellido_materno |
dirección |
teléfono |
2.4.3.3 Segunda forma normal
Una tabla se encuentra en 2a NF, si está en 1a NF y cada atributo que
NO es llave es "completamente" dependiente de la llave.
Si tenemos la tabla:
calificaciones_cursos
| id_estudiante |
depto |
clave_curso |
descripción |
calificación |
NO se encuentra en 2a NF
{ id,clave,depto} --> descripción
{clave,depto} --> descripción
Normalizando quedaría
curso
| depto |
clave_curso |
descripción |
estud_curso
| id |
depto |
clave_curso |
calificación |
|
2.4.3.4 Tercera forma normal
Un esquema relacional se encuentra en 3NF si para toda dependencia funcional X --> A:
- X --> A es una dependencia funcional trivial
o
o
- A es miembro de una llave candidata de R
Lo anterior no quiere decir que una sola llave candidata deba contener a todos los atributos de A, cada atributo de A puede estar contenido en llaves candidatas diferentes.
deptos
| nombre_depto |
extensión |
id_jefe |
empleados
| id_empleado |
nombre_depto |
id_jefe |
|
donde es evidente que nombre_depto --> id_jefe, quedaría entonces:
deptos
| nombre_depto |
extensión |
id_jefe |
empleados
|
2.5 Modelado Físico
El paso de un modelo lógico a uno físico requiere un profundo
entendimiento del manejador de bases de datos que se desea emplear, incluyendo
características como:
- Conocimiento a fondo de los tipos de objetos (elementos) soportados
- Detalles acerca del indexamiento, integridad referencial, restricciones,
tipos de datos, etc
- Detalles y variaciones de las versiones
- Parámetros de configuración
- Data Definition Language (DDL)
Como se comentó en el modelado lógico el paso de convertir el
modelo a tablas hace que las entidades pase a ser tablas (más las derivadas
de las relaciones) y los atributos se convierten en las columnas de dichas tablas.
Físicamente esta metáfora de una tabla se mapea al medio físico,
con algunas consideraciones como se menciona en las siguientes secciones.
2.5.1 Atributos
2.5.1.1 Tipos de Datos
Revisar los tipos de datos disponibles en el DBMS, en especial
- Número de dígitos en números enteros
- La precisión de los flotantes
- Cadenas de caracteres de longitud fija (char(50)) y variable (varchar(50))
- Blobs (Binary large objects) y Clobs (Character large objects)
2.5.1.2 Llaves primarias
En ocasiones se pueden presentar casos en donde la llave primaria no puede
representarse en alguno de los tipos ofrecidos por el dbms, en ese caso se podria
definir alguno y bien optar por otra llave primaria.
Importante:
Algunos dbms poseen la capacidad de "autoincrement" o "identity
property" con la cual pueden automáticamentemanipular algun atributo
para generar llaves incrementales. Pero es importante verificar: como se manejan
internamente ?, se pueden reiniciar ?, se permite especificar algun valor inicial
?.
2.5.1.3 Orden de las atributos (columnas)
Algo importante dependiendo del dbms que se utilice pero por lo general la
secuencia es:
- Columnas de longitud fija que no se actualizan frecuentemente.
- Aquellas que nunca se actualizan que por lo general tendrán longitud
variable.
- Las que se actualizan frecuentemente.
2.5.1.4 Integridad Referencial
- En la medida de lo posible indicar cuales columnas brindan o sirven de vínculo
entre 2 tablas.
- El usuario (programador) puede hacerse cargo de esto pero es mejor que el
dbms se haga cargo.
- No se recomienda en ambientes de desarrollo.
2.5.2 Indices
"Es una tabla que contiene una lista de elementos (llaves) y números
de referencia donde dichos elementos se encuentran (campos de referencia)".
Un índice es un atajo desde un campo llave hacia la localización
real de los datos.
Es el punto clave de la optimización de velocidad de toda base de datos.
Si se busca alguna tupla en base a un atributo que no tiene un índice
entonces se realiza un escaneo de la tabla completa lo cual es demasiado costoso,
por eso es recomendable usar índices en:
- Llaves primarias
- Llaves foráneas
- Indices de acceso
- Ordenamiento
No olvidar que el uso de un índice implica:
- Overhead debido a la actualización de los mismos
- Espacio adicional en disco
- Procesos batch de muchos datos pueden volverse demasiado lentos
- Manipulación de archivos adicionales por el sistema operativo
Tipos de índices:
Btrees
Bitmaps
Male 1000011101
Female 0110000010
Unknown 0001100000
|
Reverse Key
Basado en btrees pero usando el campo en orden inverso
Craig --> giarC |
Partitioned
Btrees separados en diferentes "chunks" que inclusive pueden
ser distintas particiones del disco
|
Ordered
Especificacion del btree para indicar si ordena ascendente o descendentemente |
otros serían:
Hashing
Acceso directo a los datos a través de una fórmula de
hash. El inconveniente es que requiere de espacio adicional en disco y
no es útil al recuperar "rangos" de datos.
|
Clustering
La idea es mantener las tuplas ordenadas bajo algún criterio.
El inconveniente es que requiere de espacio adicional, cuando se acaba
entonces se puede seguir insertando pero se pierde el concepto de clustering.
|
Interleaving Data
Cuando 2 tablas de antemano se sabe que se mezclarán (join)
para buscar cierta información entonces es conveniente hacer esa
mezcla en el disco. La mayoría de los dbms no lo hacen de manera
directa, se prefiere el clustering.
|
2.5.3 Structured Query Language (SQL)
CREATE
create table table_name (
column_name column_type column_modifiers,
...,
column_name column_type column_modifiers);
create table musicians(
musician_id INT,
last_name CHAR(40),
first_name CHAR(40),
nickname CHAR(40));
|
INSERT
insert into table_name (column_name, ...,
column_name)
values (value, ..., value);
insert into musicians (musician_id, last_name,
first_name, nickname)
values(2,'Lydon','John','Johnny Rotten');
|
UPDATE
update table_name
set column_name= value,
...,
column_name=value
where column_name=value;
update albums
set year=1994
where album_id=4;
update albums
set category='old music'
where year < 1980;
|
DELETE
delete from table_name
where column_name=value
delete from albums
where albums_id=4;
|
SELECT
select column_name, ..., column_name
from table_name
where column_name=value;
select title
from albums
where category='industrial';
|
JOIN
select bands.band_name
from bands,albums
where albums.category='alternative'
and bands.band_id=albums.band_id;
|
SUBQUERIES
select title
from albums,
where band_id in
(select bands.band_id
from bands, band_musician
where band_musician.musician_id=2
and bands.band_id=band_musician.band_id);
|
2.6 Bases de datos temporales
2.6.1 Temporalidad
- Relacionado con datos que implican o relacionan el tiempo.
- Es útil para poder hacer consultas sobre una situación particular en un punto particular del tiempo.
- La investigación en el área es algo que se estudia desde hace varios años, ej. Temporal SQL un artículo publicado en 1994 por Rick Snodgrass (Universidad de Arizona).
- La necesidad surge de simplificar lo que de por si es posible modelar con las técnicas tradicionales.
2.6.2 Caso práctico
2.6.2.1 Problema inicial
Si una empresa desea tener almacenada la información de sus proveedores, puede tener un esquema como:
Esquema
Supplier(ID, Name)
Sell (ID_Supplier, ID_Product)
Product(ID, Name, Description)
|
Restricciones de integridad
- Las llaves primarias son:
- Supplier(ID, Name)
- Sell (ID_Supplier, ID_Product)
- Product(ID, Name, Description)
- ID_Supplier en la relación Sell hace referencia a la llave primaria de Supplier
- ID_Product en la relación Sell hace referencia a la llave primaria de Product
de manera que una consulta como el encontrar el nombre del vendedor o los productos que vende puede ser algo muy fácil de hacer en SQL:
SELECT Name
FROM Supplier, Sell
WHERE Supplier.ID=Sell.ID_Supplier and Supplier.name='Samsung'
Otras consultas:
- Obtener los proveedores que son capaces de ofrecer al menos 1 producto.
- Obtener los proveedores que no pueden ofrecer ningún producto.
2.6.2.3 Problema de antigüedad
Sin embargo si la compañía desea mantener un histórico de los distintos productos ofrecidos por cada proveedor a lo largo de la historia, entonces el problema se complica y habria que modificar el esquema a algo como:
Supplier(ID, Name, Since date)
Sell (ID_Supplier, ID_Product, Since date) |
Qué restricciones de integridad se presentan ??
- Llaves primarias
- Supplier(ID, Name, Since date)
- Sell (ID_Supplier, ID_Product, Since date)
- Fechas válidas
- Ningún vendedor puede ofrecer productos si es que aún no tiene un contrato
Consultas:
- Obtener los proveedores que son capaces de ofrecer al menos 1 producto y para cada uno de los productos obtener la fecha desde la cual lo hace.
- Obtener los proveedores que no pueden ofrecer ningún producto y desde cuándo no pueden hacerlo.
2.6.2.4 La solución real
Supplier(ID, Name, From date, To date)
Sell (ID_Supplier, ID_Product, From date, To date) |
Nota: Algunos DBMS ofrecen la opción de incluir "intervalos (Intervals) como un tipo de dato.
Qué se está asumiendo ?
- No se pueden tener 2 contratos al mismo tiempo
- El tiempo de terminación puede estar abierto
Qué restricciones de integridad se presentan ??
- Fechas válidas
- Que el To sea mayor que el From
- Llaves primarias
- Supplier(ID, Name, From date, To date)
- Sell (ID_Supplier, ID_Product, From date, To date)
- Nota: valdría la pena normalizar la relación Supplier ?
- Qué pasa con cuestiones como "asegurarse que un producto se ofrezca en un contrato válido" ?
2.6.3 Conclusiones
- El manejo de datos temporales es delicado y no se puede tomar a la ligera.
- Las restricciones de integridad pueden llegar a complicarse al grado de que se puede llegar a hacer todo un método o Store Procedure para verificarlas.
- Las consultas siempre se podrán hacer, aunque en ocasiones serán muy complicadas y dependerán de las bondades del manejador de base de datos.
- Hay excelente material bibliográfico al respecto: